[C/C++ Syntax] #004 자료형(Data Type)

이번 글에선 데이터의 가장 기본 형태 세 가지에 대해 배워보도록 하겠습니다.
간단한게 이런게 있다 정도로 말할 수 있으면 좋겠지만, 데이터의 구조를 자세히 분석해야 앞으로의 사용에 있어서 오류를 방지할 수 있기 때문에 적어도 C언어에선 반드시 짚고 넘어가야 하는 부분입니다.
데이터의 저장 구조

일전에 컴퓨터는 이진 체계의 언어만을 사용한다고 말했었습니다. 이진 체계의 문자는 0 또는 1이라는 비트 뿐인데 어떻게 그 외의 데이터들을 표현할 수 있는 것일까요?
바로 코드화를 시켜주는 것입니다. 즉, 특정 문자를 이진수로 표현된 값에 대응이 되도록 미리 정해두는 것입니다. 예를 들어, 2라는 자연수는 이진수로 11, 31이라는 자연수는 이진수로 11111와 같이 말입니다. 문자의 형태도 마찬가지 입니다. 'a'라는 문자를 자연수 97에 먼저 대응을 시키면 이진수로 1100001로 대응이 됩니다.
하지만, 데이터의 저장은 컴퓨터 하드웨어를 기반으로 이루어지기 때문에 그 저장 범위의 물리적 한계가 있을 수 밖에 없습니다. 그래서 자료형의 크기가 정해지면 해당 자료형에서 표현할 수 있는 문자의 개수도 정해집니다. 예시로, int형의 크기가 1byte라고 하면 int형으로 표현할 수 있는 숫자는 256(=2의 8승)개가 되는 것입니다.
그리고 이 대응 관계에서 하나의 문제점이 또 발생하는데 위의 예시의 1100001이란 이진수는 자연수 97을 의미할 수도, 문자 'a'를 의미할 수도 있는 중복현상이 일어납니다. 이래서 자료형의 구분이 필요한 것입니다.
정수형(Integer Type)
이름 그대로 정수를 다루는 정수형(integer type)은 그 크기에 따라, 부호의 존재 유무에 따라 다음과 같은 종류가 있습니다.
| 부호 유무 | 자료형(data type) | 크기 (bytes) |
범위 (range) |
| 부호 있음 (signed) |
(signed) short | 2 | -32,768 ~ 32,767 |
| (signed) int | 4 | -2,147,483,648 ~ 2,147,483,647 | |
| (signed) long | 4 | -2,147,483,648 ~ 2,147,483,647 | |
| (signed) long long | 8 | -9223372036854775808 ~ 9223372036854775807 | |
| 부호 없음 (unsigned) |
unsigned short | 2 | 0 ~ 65,535 |
| unsigned int | 4 | 0 ~ 4,294,967,295 | |
| unsigned long | 4 | 0 ~ 4,294,967,295 | |
| unsigned long long | 8 | 0 ~ 18,446,744,073,709,551,615 |
표에서 보다시피 정수형에는 int형 외에도 몇 가지 종류가 더 존재하는 것을 확인할 수 있습니다. 일반적인 경우에서 기본형인 int형을 사용하지만 작은 범위의 숫자를 사용할 땐, 프로그램의 속도를 위해 short를 사용하고, 반대로 속도는 저하되지만 큰 범위의 값이 요구될 땐 long 혹은 long long을 사용합니다. CPU에따라 정수형의 크기가 다른 경우도 있으니 본인이 사용하는 개발 환경에서 자료형의 크기정도는 확인하는게 좋습니다.
범위의 값은 크기로부터 결정됩니다. 예를 들어 4비트 크기의 정수형이 있다고 가정하면, 표현할 수 있는 값의 개수는 16개입니다. 이때, 0을 기준으로 절반을 음수에 할당하고, 나머지 절반을 음수가 아닌 정수에 할당하여 범위가 -8 ~ 7이 되는 것입니다.
부호의 유무에 따른 자료형은 표에서 유추할 수 있듯이 음수에 할당하는 값들을 제외하고 양수에 추가로 할당해주는 것입니다. 일반적으로 '부호 있음'을 표시하는 signed는 생략하는 편이고, 특별히 부호가 없는 경우에 앞에 unsigned를 붙여서 사용하는 편입니다.
오버플로우(Overflow)와 언더플로우(Underflow)
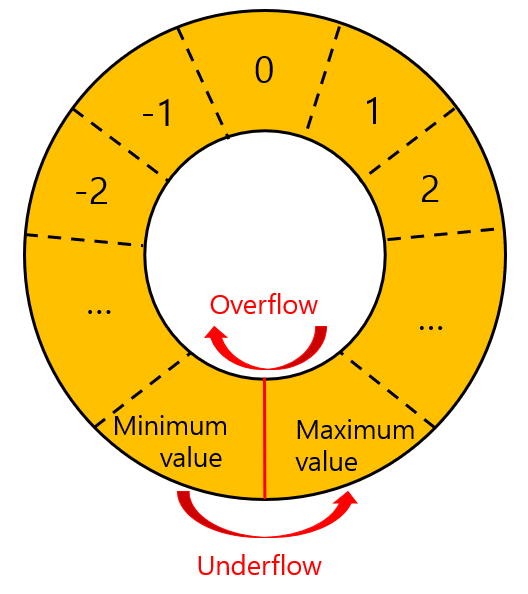
이렇게 데이터는 그 범위가 제한되어 있기 때문에 범위를 초과하는 값을 변수에 넣는 경우엔 오버플로우(Overflow) 혹은 언더플로우(Underflow)라는 현상이 발생합니다.
오버플로우는 자료형 범위 내의 최댓값보다 큰 숫자를 넣는 경우에 발생합니다. 최댓값보다 1 큰 수를 넣으면 최솟값으로 바뀌고, 2 큰 수를 넣으면 최솟값+1로 바뀌는 형태입니다. 왜 이런 현상이 발생할까요?
데이터의 표현 구조때문입니다. 편의를 위해 3비트 크기의 정수를 가정해봅시다. 부호가 있는 경우 이진수로 0000부터 1111까지 16개의 값을 -8부터 7까지의 숫자에 대응된다고 했는데요, 대응되는 비트 패턴은 다음과 같습니다.
| -4 | 100 |
| -3 | 101 |
| -2 | 110 |
| -1 | 111 |
| 0 | 000 |
| 1 | 001 |
| 2 | 010 |
| 3 | 011 |
왜 이런 형태가 나타나는지 이해가 가지 않는다면 다음 링크를 참조하길 바랍니다.
https://mimir-study-note.tistory.com/8
이런 구조에서 최댓값인 011에 1을 더하게되면 100이 되어 -4라는 결과가 나타나게 되는 것이고 언더플로우의 경우는 정확히 반대의 경우입니다.
오버플로우를 확인하기 위한 예제는 다음과 같습니다.
#include <stdio.h>
int main() {
short a = 0b0111111111111111;
int b = 0x7fffffff;
printf("a = %hd = %hx\n", a, a);
printf("b = %d = %x\n", b, b);
a = a + 1;
b = b + 1;
printf("a + 1 = %hd = %hx\n", a, a);
printf("b + 1 = %d = %x\n", b, b);
}
우선 두 변수 'a'와 'b'의 선언부에서 새로운 표현이 보입니다. 0b는 2진수를 표현하는 문자, 0x는 16진수를 표현하는 문자, 추가로 0o는 8진수를 표현하는 문자입니다. 즉, 이 프로그램에서 각 변수에는 해당 자료형의 최댓값을 넣어준 것입니다.
이에 대응하는 형식지정자를 활용해 그 값을 각각 정수와 16진수로 표현하여 출력하여 오버플로우가 나타나는 것을 확인할 수 있습니다.
부동 소수점형(Floating point Type)
다음은 실수를 나타내는 부동 소수점형(floating point type)에 대해 알아보겠습니다. 단어의 뜻을 풀어보면 소수점의 위치가 고정되어 있지 않고 떠다닌다는 말인데, 이는 정해진 크기의 비트를 일부는 소수점 이하를 나타내는데 사용하고 다른 일부는 정수부분을 나타내는 고정 소수점(fixed point) 방식과는 달리, 실수를 부호(sign), 가수(fraction)와 지수(exponent)로 나누어 비트를 각각에 할당하는 방식입니다.
예를 들자면 다음과 같은 형식입니다.

부동 소수점형은 부호의 존재 유무는 따지지 않고(항상 signed), 크기에 의해서만 그 종류가 구분되며 다음과 같습니다.
| 자료형(data type) | 크기(bytes) | 범위(range) |
| float | 4 | 약 3.4e-38 ~ 3.4e+38 |
| double | 8 | 약 1.79e-308 ~ 1.79e+308 |
(범위의 표기에서 'e±숫자' 형태는 10의 승수로 e-38은 10의 -38승과 같은 의미입니다.)
하지만 부동 소수점형을 편하게 사용하기에는 오차라는 큰 단점이 존재합니다. 그래서 대부분 float형 보다는 double형을 사용해 오차를 줄이기는 하지만 그럼에도 오차는 존재합니다. 예를 들어 1.0을 100번 더하면 100이 되어야 하지만 오차로인해 정확한 100의 값을 갖지 않게 됩니다.
이런 문제를 해결하기 위해 정해진 오차 범위 내의 값을 비교하는 경우에는 같다고 인정해 주는 코드를 짜서 사용할 수는 있지만 그럼에도 까다로움은 여전히 존재합니다.
그리고 부동 소수점형에도 오버플로우와 언더플로우가 존재하는데 정수형과는 그 표현이 조금 다릅니다. 오버플로우의 경우 결과 값을 출력해보면 inf라고 나오며, 언더플로우의 경우 결과 값을 출력해보면 0.0이라고 나오게 됩니다. (부동 소수점형에서 언더플로우는 음수 최댓값과 양수 최솟값 사이의 값을 대입한 경우 나타납니다.)
문자형(Character Type)
문자(character)는 하나의 글자, 숫자, 기호 등을 의미하는 말로, 'a', '0', '+' 등의 것들로 컴퓨터와 자연어의 소통을 위해서 가장 필요한 자료형이라고 볼 수 있습니다.
(참고로 문자로 표현된 숫자와 숫자 그 자체는 다릅니다. 문자는 이미지를 코드화 했다고 생각하면 됩니다.)
| 자료형(data type) | 크기(byte) |
| char | 1 |
이전 글에서 말했듯이 문자는 각각 서로 다른 음이 아닌 정수에 대응된 값이 비트화 된 형태라고 할 수 있습니다. 그래서 이를 모두가 사용하기 위해선 규격이 필요하고 이를 아스키(ASCII : American Standard Code for Information Interchange)라고 부르고, 표로 정리한 것을 아스키 코드 표 라고 말합니다.
아스키 코드 표는 다음과 같습니다.

십진수로 0~31, 127은 제어문자에 해당하므로 32~126에 해당하는 96개의 문자가 콘솔 창에 출력 가능한 일반문자인 것입니다.
이렇게 128개의 문자를 표현하기 위해선 7비트만 있으면 되지만, char의 크기는 1바이트이므로 절반 정도가 비게 되는데 이는 확장된 아스키 코드들로 대응되어 있습니다.
문자형의 독특한 점은 정수와 연산이 가능하다는 점인데요, 이는 다음 장인 수식과 연산자 파트에서 자세하게 다루도록 하겠습니다.